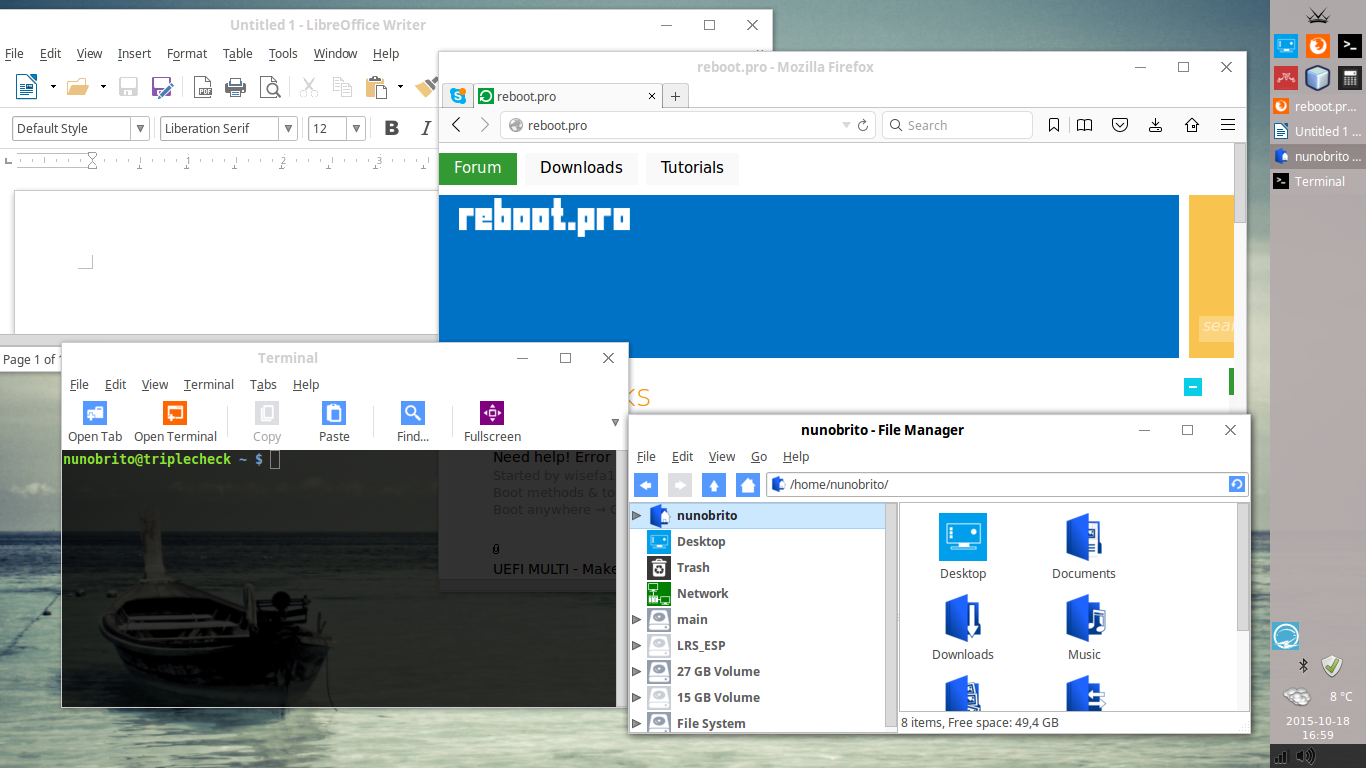
This weekend finally took the time to upgrade Windows 7 on my old laptop and try out that button on the system tray with the free Windows 10 install.
Was surprised, that was an old laptop from 2009 that came with the stock
Windows 7 version and still worked fairly OK. Have to say that the new interface, which is
indeed looking better and simpler. The desktop is enjoyable, but the fact that this Windows version beams
up to Microsoft whatever I'm doing with on my own laptop is still a bother and a cold shill on the spine.
On my newer laptop I run Linux Mint. This is an old version installed back in 2013 and could
really use an update. So, since it was upgrade-weekend I've decided to simply go ahead and bring up this Linux machine to a more recent version of Mint and see what had changed over the
past years. While doing this upgrade, a question popped up: "how about
adding the design of Windows 10 with Linux underneath, would it work?"
And this is the result:
The intention wasn't creating a perfect look-a-like, but (in my opinion) to try mixing and getting a relatively fresh looking design based on Windows, at the same time without opening
hand from our privacy.
Operating System
I've got Linux Mint 17.2 (codename Olivia, Cinnamon edition for x64) downloaded from
http://www.linuxmint...tion.php?id=197
Instead of installing to disk, this time I've installed and now run the
operating system from a MicroSD card connected to the laptop through the
SD reader using an SD adapter. The MicroSD is a Samsung 64Gb with
advertised speed of 40Mb/s for read operations. Cost was ~30 EUR.
Installing the operating system followed the same routine steps as
one would expect. There is a GUI tool from within Linux mint to write the
DVD ISO into a pendisk connected on your laptop. Then boot from the USB
and install the operating system on the MicroSD, having the boot entry
added automatically.
Window 10 theme and icons
Now that the new operating system is running, we can start the customization.
The windows style you find on the screenshot can be downloaded from:
http://gnome-look.or...?content=171327
This theme comes with icons that look exactly like Windows 10, but that wasn't
looking balanced nor was our intention to copy pixel per pixel the icons. Rather, the intention was re-using the design guidelines. While looking for options, found Sigma Metro which resembled what was needed:
http://gnome-look.or...?content=167327
If you look around the web, you'll find instructions on how to change the window themes and icons. Otherwise if you get into difficulties, just write me a message and I'll help.
Firefox update and customization
Install Ubuntu Tweaks. From there, go to Apps tab and install the most
recent edition of Firefox because the one included on the distro is a
bit old.
Start changing Firefox by opening it up and going to "Addons" -> "Get
Addons". Type on the search box "Simple White Compact", this was the
theme that I found the simplest and will change the
browser looks, from icons to tab position as you can see on the screenshot. Other extensions that you might enjoy
adding while making these changes are "Adblock Plus" to remove ads, "Tab Scope" to show miniatures when
browsing tabs and "Youtube ALL HTML5" to force youtube running without
using the Adobe Flash Player.
Office alternative and customization
Then we arrive to Office. I only keep that oldish laptop because it has the
Adobe Reader (which I use for signing PDF documents) and Microsoft Office for the cases when I need to modify documents and presentations without getting them
to look broken. So, I was prepared this time to run both apps using Wine (it
is possible) but decided to first do an update on the alternatives and try using only Linux
native apps. Was not badly surprised.
LibreOffice 4.x is included by default on the distro. Whenever I'd use it, my slides formatted in MS Office would look broken and unusable. Decided to download and try out version 5.x and to my surprise notice that these issues are
gone. Both the slides and word documents are now properly displayed with just
about the same results that I'd expected from Microsoft office. I'm happy.
To install LibreOffice 5.x visit
https://www.libreoff...reoffice-fresh/
For the Linux edition, read the text document with instructions.
Quite straightforward, just one command line to launch the setup. So, I was happy with LibreOffice as a complete
replacement to Microsoft (no need to acquire licenses nor run office
through Wine). However, those icons inside LibreOffice still didn't look good, they looked old. On
this aspect the most recent version of Microsoft Office simply "looks" better. I wanted LibreOffice to
look that way too. So, got icons from here:
http://gnome-look.or...?content=167958
It wasn't straightforward to find out where the icons could be placed
because the instructions for version 4.x no longer apply. To help you,
the zip file with icons need to be placed inside:
/opt/libreoffice5.0/share/config/
Then you can open up "writer" and from the "Tools" -> "Options"
-> "View" choose "Office2013" and get the new icons being used. The
startup logo of LibreOffice also seemed too flashy and could be changed.
So I've changed with the one available at
http://gnome-look.or...?content=166590
Just a matter of overwriting the
intro.png image found at:
/opt/libreoffice5.0/program
Alternative to Adobe Reader for signing PDF
Every now and then comes a PDF that requires being printed, signed by pen and then scanned to send again to the other person. I stopped doing this kind of thing some time ago by adding a
digital signature that includes an image of my handwritten signature on
the document. This way there's no need to print nor scan any papers. Adobe
Reader did a good work on this task but getting it to run on Wine with
the signature function was not straightforward.
Started looking for a native Linux alternative and found "Master PDF
Editor". The code for this software is not public but I couldn't find other options and these were the only ones that
provided a native Linux install supporting digital handwritten
signatures:
https://code-industr...asterpdfeditor/
If you're using this tool for business, you need to acquire a license. Just
for home-use is free of cost. Head out to the
download page and install the app. I was surprised because it looked
very modern, simple and customizable. I'll buy a license for this tool, does exactly what I needed. Having LibreOffice and MasterPDF as
complete alternative to MS Office and Acrobat, there is no more valid reason (on
my case) to switch back the old laptop whenever editing documents. This can
be done with same (or even better) quality from Linux now.
Command line
A relevant part of my day-to-day involves the use of
command line. In Linux this is a relatively pleasant task because the terminal window can
be adjusted, customized and never feels like a second class
citizen inside the desktop. With these recent changes that were applied, was
now possible to improve further the terminal window by showing the tool bar (see the screenshot).
Open a terminal, click on "View"
-> "Show tool bar". Usually I'm against adding buttons, but that tool bar has
a button for pasting clipboard text directly onto the console. I know that can be done by the keyboard using "Ctrl '+ Shift + V", but found it very practical to just click on a single button and paste the text.
Non-Windows tweaks
There are tweaks only possible on Linux. One of my favorite keeps
being the "Woobly windows". Enable Compiz on the default desktop
environment:
http://askubuntu.com...-wobbly-windows
With Compiz there are many tweaks possible, I've kept them to a
minimum but certainly is refreshing to use some animations rather than the
plain window frames. If you never saw this in action, here is a video example:
https://www.youtube.com/watch?v=jDDqsdrb4MU
Skype alternatives
Many of my friends and business contacts use Skype. It is not safe, it is not private, and I'd prefer to use a non-Microsoft
service because the skype client gets installed on my desktop. Who knows
what it can do on my machine when it is running on the background. One interesting alternative that I've found was launching the
web-edition of skype that you find at
https://web.skype.com/
From firefox, there is the option to "Pin" a given tab. So I've
pinned skype as you can see on the screenshot, and now opens automatically whenever the browser
gets open, in practice bringing it online when I want to be reachable. A
safe desktop client and alternative would be better, this is nowhere a perfect solution but rather a
compromise that avoids installing the skype client.
Finishing
There are more small tweaks happening to adjust the desktop for my case, but
what is described above are the big blocks to help you reach this kind of design in case you'd like to do something similar.
If you have any questions or get stuck at any part of customization, just let me know.
Have fun!
:-)